The platform · Compliant AI for credentialing bodies
Human + AI, better together.
From rubric to report. Conversational, written and Excel-based assessment. AI grading on a transparent rules engine. Multi-modal feedback for every learner. Governance you select per assessment.
The platform, end-to-end
Eight first-class capabilities, every one with a Principal Consultant deep-dive behind it.
- Pre-launch calibration with synthetic submissions
- Evaluation Copilot writes the marking guide for you
- Layered Rules Engine — transparency by architecture
- Four rubric types, mixed within a single question
- Short-Term Memory for fair multi-part grading
- Conversational, written and Excel-based submissions
- Multi-modal feedback bundle: PDF, podcast, avatar video, heat-map
- Three-tier governance you select per assessment

Pre-launch
Train the Grader Mode
Before the first script is marked, create alignment. Generate synthetic submissions for each grader, practice applying criteria, and review readiness with alignment reports.
- Create a bank of synthetic attempts that reflect your rubric
- Run calibration rounds; capture rationales and edge-cases
- Sign-off when variance is inside tolerances
What's included:
- Synthetic submission generator
- Calibration rounds & variance tracking
- Readiness & alignment report export

During grading
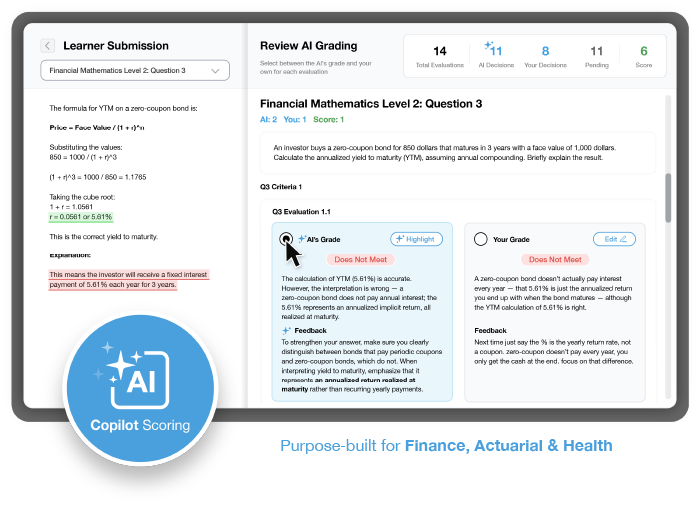
AI Copilot
Choose the flow that fits your governance. Let AI grade first for speed, then review; or grade internally first, then compare with AI. Mix and match outcomes and comments.
- Side-by-side comparison of human and AI outcomes
- Selective adoption of scores and feedback
- Audit trail with who/what/when for each decision
Controls:
- Policy-based thresholds for auto-accept vs human review
- Role-based permissions and lock-step workflows
- Exportable evidence for QA and appeals

Spreadsheet assessments
Formula Validation
Automatically check spreadsheet formulas alongside results to provide richer, fairer feedback.
- Rules > Actions toggle to enable checks
- Support for common Excel functions and ranges
- Feedback that differentiates method vs outcome
Why it matters:
- Credit methodology as well as final answers
- Reduce manual rework and back-and-forth
- Improve consistency across graders

Competency frameworks
Diagnostics Copilot
Connect grading outcomes directly to your competency framework. Model it once and the platform auto-tags each new assessment so results roll up cleanly to competencies.
- Heat-map each learner against domains and levels
- Highlight strengths and focus areas with targeted feedback
- Deliver personalised outcomes in the candidate's report
What's included:
- Framework modeller for domains, levels and descriptors
- Automatic tagging of items & outcomes across assessments
- Cohort and item heat-maps with report integration

Post-session
Examiner's Report
Turn results into meaningful insight in minutes. Generate an overall performance summary, highlight strengths and weaknesses, and drill into every evaluation.
- One-click cohort summary with visuals
- Exportable to PDF/CSV
- Share with educators and learners
What you get:
- Summary trends & variance
- Item-level analysis and exemplars
- Recommendations for improvement
More platform capabilities
Beyond the headline features, each with a Principal Consultant deep-dive behind it.
Evaluation Copilot
Writes the detailed grading rules for you in minutes, then hands them back for human review. Hours of rule-writing become minutes of approval.
Read the deep dive →Rules Engine
A layered, transparent execution environment where every rule is text, every aggregation is structured, and every grading decision is auditable rule-by-rule.
Read the deep dive →Three-Tier Governance
Select the level of rigour per assessment. The choice cascades through psychometrics, AI controls, reporting and standards alignment.
Read the deep dive →Conversational Assessments
Candidates speak their answers. The platform produces an intelligent summary the candidate reviews before submission.
Read the deep dive →Multi-Modal Feedback Bundle
PDF, audio podcast, avatar video and competency heat-map — generated automatically from a single grading process for every learner.
Read the deep dive →Task-Level Grader Routing
Send specific tasks to specific specialist graders, the way real exam boards already work.
Read the deep dive →AI-Plus-Self-Grade
A reflective intervention for formative work. AI grades, the candidate reviews and responds, and the act of reviewing is where the learning happens.
Read the deep dive →SCORM & LMS Integration
Drops into Moodle, Cornerstone, Docebo, Workday, Canvas, Blackboard via SCORM. HTML deployment for everything else.
Read the deep dive →Security & Governance
- Three-tier governance selected per assessment
- Transparent rules engine — every grading decision auditable
- AI optional, configured per assessment
- ISO 42001 / 23894 aligned, EU AI Act ready
- AERA, APA, NCME and NCCA mapped
- SSO (SAML/OIDC), RBAC, regional residency
Deployment & Integration
- SCORM export to Moodle, Cornerstone, Docebo, Workday, Canvas, Blackboard
- HTML deployment for non-SCORM environments
- Claude on Amazon Bedrock — prompts stay in your AWS perimeter
- API and Salesforce connector for custom workflows
- Cloud with regional data residency, private tenant options
Beyond the platform. Assess for Learning is the platform layer underneath our broader consulting practice. Where your audit cycle requires more — a full AI register with risk classification, an audit pack mapped to the Testing Standards and EU AI Act, inter-rater agreement evidence across your examiner panel — the AI Systems Integration practice delivers the engagement. See the services page for scope and approach.

Globebyte is an Associate sponsor of the e-Assessment Association — the global professional body championing the future of digital assessment. 5,000+ members across 50+ countries.
Insights from our Principal Consultants
Beyond the platform itself — the learner experience, governance authority, and credentialing strategy thinking behind the work.
Avatar Video Feedback: A Personalised Highlight Reel for Every Learner
Personal feedback used to be too expensive to scale. Avatar video breaks the trade-off and delivers it to every learner, automatically.
Read more →The Reflection Podcast: Feedback Learners Actually Listen To
Most assessment feedback gets read once, if at all. Here is what happens when feedback becomes a conversation instead of a verdict.
Read more →AI Optional: The Credentialing Platform That Does Not Force AI On You
The AI conversation in credentialing has become binary. Real credentialing organisations need a third option: genuine choice, configured per assessment.
Read more →Skills Gap Screening: Putting the Right Learner on the Right Path Before They Enrol
Most workforce development programmes do not have the screening capability they need, and they know it. Here is what evidence-based placement looks like.
Read more →AI Governance for Credentialing: ISO 42001 and 23894 Explained
Two ISO standards give credentialing bodies a practical AI operating model that survives an audit. Here is how to apply them without freezing innovation.
Read more →Inter-Rater Agreement and AI Scoring: The Reliability Evidence You Now Need
AI is a rater, not an exception. Here is the inter-rater agreement, bias, fairness, and drift evidence credentialing programmes now need for AI scoring.
Read more →Assess for Learning FAQs
No. The AI Copilot augments graders and keeps educators in control. You decide the flow and acceptance policy. Read how the grading copilot works →
AI runs inside a layered rules engine where every evaluation criterion is explicit and editable. The grading is auditable rule-by-rule. Why transparency is the architecture →
No. Assess for Learning exports as SCORM for Moodle, Cornerstone, Docebo, Workday, Canvas and Blackboard, and as HTML for everything else. How LMS integration works →
The three-tier governance model maps to AERA, APA, NCME, ISO 17024, ISO 42001 and the EU AI Act. EU AI Act for credentialing → · ISO 42001 explained →
Yes. Task-level grader routing sends each task to the right subject matter expert, the way real exam boards already operate. Read more →
Yes. Three-tier governance is selected per assessment, so the same platform runs everything from CPD practice to high-stakes summative under the right level of rigour. Three-tier governance →
Yes. Candidates speak their answers, the platform produces an intelligent summary, the candidate reviews and confirms. Conversational assessments →
A multi-modal bundle: detailed PDF, audio reflection podcast, avatar video, competency heat-map and next-step recommendations — all from one grading process. The feedback bundle →
We don't train foundation models on your data. Claude runs on Amazon Bedrock so prompts and context stay inside your AWS perimeter. SSO and RBAC enforce access; you control retention and residency.
Book a demo. We'll map a pilot to your rubric and show an end-to-end flow including the Examiner's Report and Precision Report.
See Assess for Learning in your context
Book a 30-minute demo. We'll map a pilot to your rubric, walk through the rules engine, AI Copilot, multi-modal feedback bundle and the Examiner's Report with your data shape.